I love autocomplete. It's one of those things that everyone realizes they need early in their search journey. And it's usually the first thing people start with right after their search relevance is at a good enough baseline.
I love it so much that it's the first chapter I wrote for AI-Powered Search as a baby-step into vector search. That chapter, though, uses fancy tools like SpaCy and self-hosted transformer models. But what if you're not ready for that yet? You've already got Elastic or OpenSearch and want something more out-of-the-box? Well, dear reader, you have once again found yourself in the right place.
One of my main gripes about just basic autocomplete is that nobody really tells you how to do it. The internet is filled with half-baked Medium posts, Stackoverflow questions, and incomplete-yet-official docs from the engines. This is something missing from the internet, and I can stand it no longer.
Give the people what they want
Before diving into a solution, we need to be diligent and start from the problem: what people expect when they start typing into a search bar.
The problem is that people may or may not know what to search for. More importantly: they might not know what content your site has, or they might not know how to express themselves.
So, when people start typing, they want to see two kinds of suggestions: (1) pages, and (2) what to search.
Both are very helpful, and as a side benefit also exist to save the people's precious fingers from the brutal exhaustion of further typing.
Let's see an example implementation from the eponymous standard set by Google long ago:
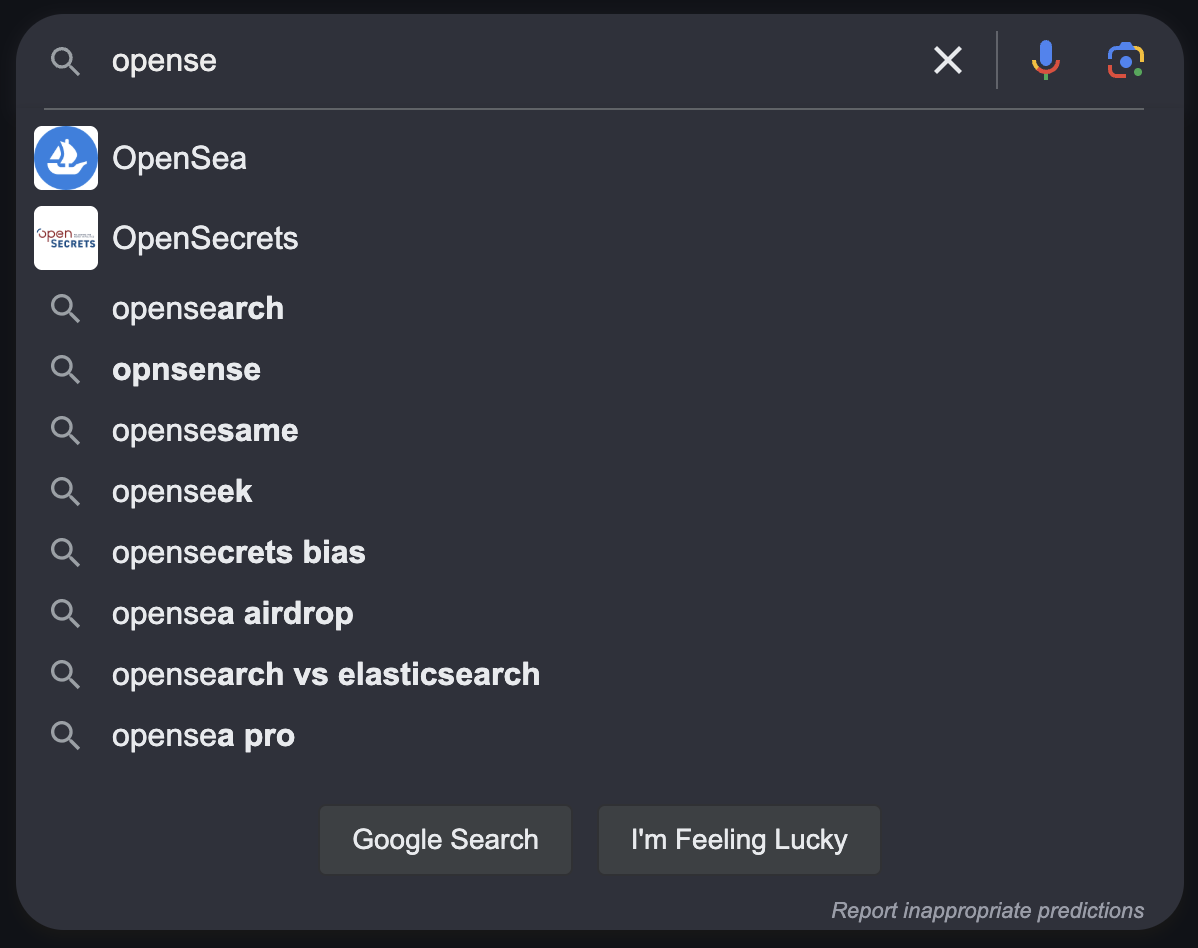
Google's autosuggest for ‘opense'
There you have it, a solid mix of terms and sites to choose from: a simple-to-understand list of things that people might be looking for.
So, we have our problem, and we have a solution direction. But what lore exists for us?
Existing Documentation
If you were lucky, when web-searching how to solve autocomplete for Elastic or OpenSearch, you've stumbled upon this very article.
If you were almost-lucky, you found this article in the OpenSearch docs.
I will say, it's an excellent article. But it's deceptive. Deviously deceptive. Because it leaves out a key detail that you won't realize until you're knee-deep in implementing some of its recommended approaches.
That and all other articles are dependent on you already having short phrases and words that you want to suggest! That's right. It doesn't show you how to generate suggested terms or phrases from actual documents that everyone uses. The closest you will get are titles (great for the pages suggestions) or nominal metadata such as categories (which is not nearly comprehensive enough to cover all potential search prefixes).
You've got paragraphs of descriptions and body text and are looking for a way to produce your suggestion vocabulary, and NOBODY tells you how. It's something you have to figure out on your own! In a cave! With a box of scraps! (until now)
How did they do it?!
This is what we're going to build:
Let's get crackin'
The other thing I don't like about many articles is they dance around what to do. An analyzer here, a query technique there, maybe some trite examples of content. We're going to use an actual example of actual content, and walk through exactly what to do, one step at a time.
Our Content Example
Surprise! We're using Bonsai's website content. Bonsai has about 260 pages of juicy texty material. It's a mix of company info, policies, technical docs, and blog posts. Here's what an actual article looks like once it's ready for ingestion into OpenSearch:
{
"docid": "da93fd39-8d4f-6051-66f7-a011dfce08a8",
"url": "https://bonsai.io/docs/shard-primer",
"title": "Shard Primer",
"description": "This article explains what shards are, how they work, and how they can best be used.",
"body": "Shard Primer\nFor people new to Elasticsearch, shards can be a bit of a mystery. Why is it possible to add or remove replica shards on demand, but not primary shards? What's the difference? ... article continues."
}
That's it. Other documents have more metadata (like author and publish date), but this document is simple, and a worthy example. Like all texty documents, it is choc-full of words and phrases that people might want suggestions for: "primary shards", "replication", "high-availability", "overallocation" and many more.
Find out how we can help you.
Schedule a free consultation to see how we can create a customized plan to meet your search needs.
Our Baseline Index Configuration
I'm old school. I call Mappings and Settings a schema, like someone from the dark ages of search, when we hand coded Java plugins and shouted in anger at classpaths.
This is what the schema looks like starting out. It doesn't have the things we need yet for autocomplete, it's probably similar to how you're starting… it is concise and ready to index a bunch of content for our site.
{
"mappings": {
"properties": {
"docid": { "type": "keyword" },
"url": { "type": "keyword", "copy_to":["url_hierarchy"] },
"image": { "type": "keyword" },
"published": { "type": "date" },
"modified": { "type": "date" },
"author": { "type": "text", "analyzer": "analyze_names"},
"url_hierarchy":{ "type": "text", "analyzer": "analyze_urls"},
"url_depth": { "type": "integer" },
"title": { "type": "text", "analyzer": "analyze_english"},
"description": { "type": "text", "analyzer": "analyze_english"},
"body": { "type": "text", "analyzer": "analyze_english","term_vector": "with_positions_offsets"}
}
},
"settings": {
"analysis": {
"filter": {
"english_stop": {
"type": "stop",
"stopwords": "_english_"
},
"english_stem": {
"type": "stemmer",
"language": "english"
},
"english_possessive_stem": {
"type": "stemmer",
"language": "possessive_english"
}
},
"tokenizer": {
"path_hierarchy_tokenizer": {
"type": "path_hierarchy"
}
},
"analyzer": {
"analyze_urls": {
"type": "custom",
"tokenizer": "path_hierarchy_tokenizer"
},
"analyze_names": {
"type": "custom",
"tokenizer": "standard",
"filter": [
"lowercase",
"english_possessive_stem"
]
},
"analyze_english": {
"type": "custom",
"char_filter": ["html_strip"],
"tokenizer": "standard",
"filter": [
"lowercase",
"english_possessive_stem",
"english_stop",
"english_stem"
]
}
}
},
"index": {
"number_of_shards": 1,
"number_of_replicas": 0
}
}
}
As bare-bones as you can get. This might not be perfectly relevant (I have lots of other stuff going on in the real index), but it's good enough for illustration of a starting point for autocomplete.
Steps for implementation
This is the outline of the things we're going to add to reach autocomplete happiness. First, I'll list the pieces, then I'll define them.
- A
completionfield with anEdge-ngramtokenizer - A
suggest_wordsfield withfielddataset totrue, and a less aggressive stemmer - A
suggest_phrasesfield withfielddataset totrue, and a shingles analyzer - A query, that uses the above fields to suggest search terms
- Post-processing (optional), which we can only do in some basic client-side code.
Step 1: Completions using Edge-ngrams
Our first step is a double-whammy. We'll use a new completion field to get page suggestions AND match content to drive
our search term suggestions. If you wanted to only provide page suggestions, you can implement this one step and stop!
When typing, we need to be able to find where possible terms begin (the prefix). We could use match_prefix_query, but
that's slow. So instead we're going to speed things up at the cost of memory by using the edge-ngram tokenizer. Rather
than rewrite what this does, I'll link to the canonical reference if you want to learn
more: https://opensearch.org/docs/latest/search-plugins/searching-data/autocomplete/#edge-n-gram-matching
For the edge-ngram tokenizer, we need a tokenizer, an analyzer, and a field:
Tokenizer
"edge_ngram_tokenizer": {
"type": "edge_ngram",
"min_gram": 1,
"max_gram": 25,
"token_chars": [
"letter",
"digit",
"punctuation"
]
}
Analyzer:
"edge_ngram_analyzer": {
"type": "custom",
"char_filter": [
"html_strip"
],
"tokenizer": "edge_ngram_tokenizer",
"filter": [
"lowercase"
]
}
Field:
"completion": {
"type": "text",
"analyzer": "edge_ngram_analyzer",
"fields": {
"raw": {
"type": "keyword"
}
}
}
With all three of the above in place, we need to modify some existing fields to copy them into the completion field. For
this guide, we're going to use both title and description.
// ...
"title": { "type": "text", "analyzer": "analyze_english", "copy_to":["completion"]},
"description": { "type": "text", "analyzer": "analyze_english", "copy_to":["completion"]},
// ...
For our example, I'm going to create a new index, with our new schema, and reindex content into it. That way we can see things step-by-step. Just copy this thing straight into your dev tools (Kibana or Dashboards), and run!
# Step 1: Completions point
PUT /autocomplete-example
{
"mappings": {
"properties": {
"docid": { "type": "keyword" },
"url": { "type": "keyword", "copy_to":["url_hierarchy"] },
"image": { "type": "keyword" },
"published": { "type": "date" },
"modified": { "type": "date" },
"author": { "type": "text", "analyzer": "analyze_names"},
"url_hierarchy":{ "type": "text", "analyzer": "analyze_urls"},
"url_depth": { "type": "integer" },
"title": { "type": "text", "analyzer": "analyze_english", "copy_to":["completion"]},
"description": { "type": "text", "analyzer": "analyze_english", "copy_to":["completion"]},
"body": { "type": "text", "analyzer": "analyze_english", "term_vector": "with_positions_offsets"},
"completion": {
"type": "text",
"analyzer": "edge_ngram_analyzer",
"fields": {
"raw": {
"type": "keyword"
}
}
}
}
},
"settings": {
"analysis": {
"filter": {
"english_stop": {
"type": "stop",
"stopwords": "_english_"
},
"english_stem": {
"type": "stemmer",
"language": "english"
},
"english_possessive_stem": {
"type": "stemmer",
"language": "possessive_english"
}
},
"tokenizer": {
"edge_ngram_tokenizer": {
"type": "edge_ngram",
"min_gram": 1,
"max_gram": 25,
"token_chars": ["letter", "digit", "punctuation"]
},
"path_hierarchy_tokenizer": {
"type": "path_hierarchy"
}
},
"analyzer": {
"analyze_urls": {
"type": "custom",
"tokenizer": "path_hierarchy_tokenizer"
},
"edge_ngram_analyzer": {
"type": "custom",
"tokenizer": "edge_ngram_tokenizer",
"filter": [
"lowercase"
]
},
"analyze_names": {
"type": "custom",
"tokenizer": "standard",
"filter": [
"lowercase",
"english_possessive_stem"
]
},
"analyze_english": {
"type": "custom",
"char_filter": ["html_strip"],
"tokenizer": "standard",
"filter": [
"lowercase",
"english_possessive_stem",
"english_stop",
"english_stem"
]
}
}
},
"index": {
"number_of_shards": 1,
"number_of_replicas": 1
}
}
}
POST _reindex
{
"source": {
"index": "bonsai"
},
"dest": {
"index": "autocomplete-example"
}
}
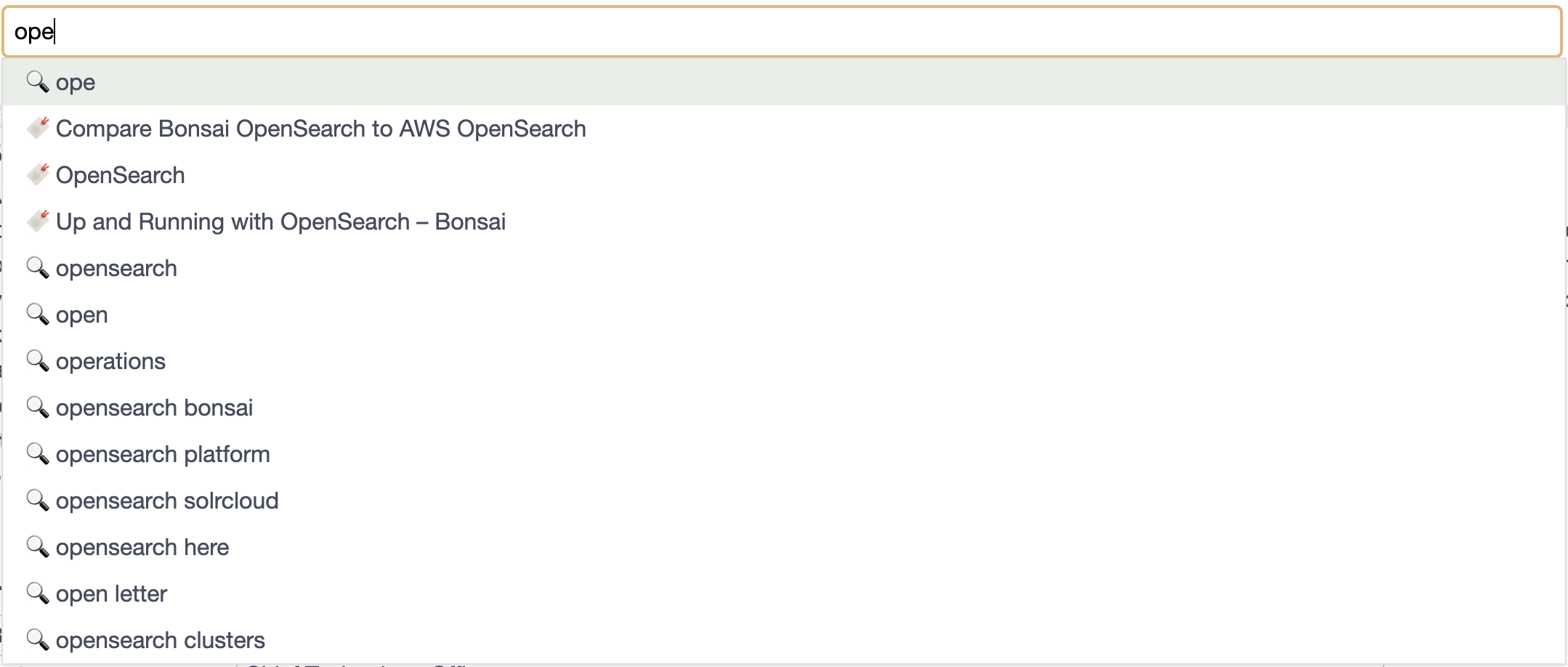
OK! We're ready to try our first query! It's really basic, and works well. I'm going to imagine someone got as far as
typing "ope", using a match on completion with our prefix.
POST /autocomplete-example/_search
{
"query": {
"match": {
"completion": "ope"
}
},
"_source": [
"title",
"url"
],
"size": 3
}
Results in...
{
"took": 61,
"timed_out": false,
"_shards": {
"total": 1,
"successful": 1,
"skipped": 0,
"failed": 0
},
"hits": {
"total": {
"value": 178,
"relation": "eq"
},
"max_score": 6.6680512,
"hits": [
{
"_index": "autocomplete-example",
"_id": "bfb9fe25-8742-1067-026a-428025c41672",
"_score": 6.6680512,
"_source": {
"title": "Compare Bonsai OpenSearch to AWS OpenSearch",
"url": "https://bonsai.io/vs/amazon-opensearch-service"
}
},
{
"_index": "autocomplete-example",
"_id": "db637423-cf63-24c5-32ac-68c309c62fbe",
"_score": 6.501189,
"_source": {
"title": "Up and Running with OpenSearch – Bonsai",
"url": "https://bonsai.io/blog/up-and-running-with-opensearch"
}
},
{
"_index": "autocomplete-example",
"_id": "9a160271-5f4b-fc7f-1215-fdf63f2d9cc3",
"_score": 6.486245,
"_source": {
"title": "OpenSearch",
"url": "https://bonsai.io/category/opensearch"
}
}
]
}
}
Well, that's pretty freakin' great.
Step 2: Suggest Words
Suggesting individual words is pretty easy. I don't know why the guides don't at least show this basic example. Here's what we need:
- A new field:
suggest_word - Less aggressive stemming
fielddata=true
We already have the stemmer we want in our filters: english_possessive_stem. We'll use that and remove stop words (we
don't want be silly and suggest words like "the" when people are looking for something like "theme")
At query time, we're going to use the significant_terms aggregation on our new suggest_word field. This is our
shouldn't-be-a-secret sauce. From the OpenSearch docs:
“
The
significant_termsaggregation lets you spot unusual or interesting term occurrences in a filtered subset relative to the rest of the data in an index.”
Analyzer
"analyze_english_exactish": {
"type": "custom",
"char_filter": [
"html_strip"
],
"tokenizer": "standard",
"filter": [
"lowercase",
"english_possessive_stem",
"english_stop"
]
}
Field
"suggest_word": {
"type": "text",
"analyzer": "analyze_english_exactish",
"fielddata": true
}
With those in place, we need some copy_tos. I'm going to use title and description. You can and should also
experiment when you add body.
...
"title": {
"type": "text",
"analyzer": "analyze_english",
"copy_to": [
"completion",
"suggest_word"
]
},
"description": {
"type": "text",
"analyzer": "analyze_english",
"copy_to": [
"completion",
"suggest_word"
]
}
...
OK! Let's rebuild and reindex. Here's the entire step all rolled into one copypasta-for-ya-kibana.
Step 2: Suggest Words.
Let's delete the old example to make way for the new:
DELETE /autocomplete-example
Add the new one:
PUT /autocomplete-example/
{
"mappings": {
"properties": {
"docid": { "type": "keyword" },
"url": { "type": "keyword", "copy_to":["url_hierarchy"] },
"image": { "type": "keyword" },
"published": { "type": "date" },
"modified": { "type": "date" },
"author": { "type": "text", "analyzer": "analyze_names"},
"url_hierarchy":{ "type": "text", "analyzer": "analyze_urls"},
"url_depth": { "type": "integer" },
"title": { "type": "text", "analyzer": "analyze_english", "copy_to":["completion","suggest_word"]},
"description": { "type": "text", "analyzer": "analyze_english", "copy_to":["completion","suggest_word"]},
"body": { "type": "text", "analyzer": "analyze_english", "term_vector": "with_positions_offsets"},
"completion": { "type": "text", "analyzer": "edge_ngram_analyzer", "fields": { "raw": { "type": "keyword" } } },
"suggest_word": {
"type": "text",
"analyzer": "analyze_english_exactish",
"fielddata": true
}
}
},
"settings": {
"analysis": {
"filter": {
"english_stop": {
"type": "stop",
"stopwords": "_english_"
},
"english_stem": {
"type": "stemmer",
"language": "english"
},
"english_possessive_stem": {
"type": "stemmer",
"language": "possessive_english"
}
},
"tokenizer": {
"edge_ngram_tokenizer": {
"type": "edge_ngram",
"min_gram": 1,
"max_gram": 25,
"token_chars": ["letter", "digit", "punctuation"]
},
"path_hierarchy_tokenizer": {
"type": "path_hierarchy"
}
},
"analyzer": {
"analyze_urls": {
"type": "custom",
"tokenizer": "path_hierarchy_tokenizer"
},
"edge_ngram_analyzer": {
"type": "custom",
"tokenizer": "edge_ngram_tokenizer",
"filter": [
"lowercase"
]
},
"analyze_names": {
"type": "custom",
"tokenizer": "standard",
"filter": [
"lowercase",
"english_possessive_stem"
]
},
"analyze_english": {
"type": "custom",
"char_filter": ["html_strip"],
"tokenizer": "standard",
"filter": [
"lowercase",
"english_possessive_stem",
"english_stop",
"english_stem"
]
},
"analyze_english_exactish": {
"type": "custom",
"char_filter": ["html_strip"],
"tokenizer": "standard",
"filter": [
"lowercase",
"english_possessive_stem",
"english_stop"
]
}
}
},
"index": {
"number_of_shards": 1,
"number_of_replicas": 1
}
}
}
POST _reindex
{
"source": {
"index": "bonsai"
},
"dest": {
"index": "autocomplete-example"
}
}
Query time. Same term "ope", and with the page hits (results) omitted for this example, but they are the same as in Step 1.
POST /autocomplete-example/_search
{
"query": {
"match": {
"completion": "ope"
}
},
"aggs": {
"significant_words": {
"significant_terms": {
"field": "suggest_word",
"include": "ope.*",
"min_doc_count": 1
}
}
},
"_source": {
"include": [
"title",
"url"
]
},
"size": 0
}
Some important details above: the include param for the significant_terms aggregation. We don't just want to show any
terms! Without the include pattern, we'd get some weirdness (go ahead and try it for fun in your content).
We are also setting min_doc_count to 1. This is because our corpus is tiny. If you have thousands or millions of
documents, increase this number to improve performance.
Let's see the results from the query:
{
"took": 28,
"timed_out": false,
"_shards": {
"total": 1,
"successful": 1,
"skipped": 0,
"failed": 0
},
"hits": {
"total": {
"value": 178,
"relation": "eq"
},
"max_score": null,
"hits": []
},
"aggregations": {
"significant_words": {
"doc_count": 178,
"bg_count": 259,
"buckets": [
{
"key": "opensearch",
"doc_count": 35,
"score": 0.08947733871985859,
"bg_count": 35
},
{
"key": "open",
"doc_count": 4,
"score": 0.010225981567983837,
"bg_count": 4
},
{
"key": "operations",
"doc_count": 2,
"score": 0.005112990783991919,
"bg_count": 2
},
{
"key": "operational",
"doc_count": 1,
"score": 0.0025564953919959593,
"bg_count": 1
}
]
}
}
}
Do you love it? I think you love it. Let's keep going.
Find out how we can help you.
Schedule a free consultation to see how we can create a customized plan to meet your search needs.
Step 3: Suggest Phrases
You might look above and think "hey, that's good enough." And that is totally fine. While writing this guide, I was in the midst of doing everything, and I thought I might stop at just words.
But, phrases are powerful. They show you combinations of things and, especially when you grow into millions of documents ripe for discovery, they're far more useful than just single words to help narrow the search faster.
What we need:
- A new field
suggest_phrase - Less aggressive stemming (same as step 2)
fielddata=true(same as step 2)- Shingles (in our case,
bigramsandtrigrams)
What are shingles, bigrams, and trigrams? It's easier to just explain it. Let's use one of the titles above "Compare Bonsai OpenSearch to AWS OpenSearch" for an example.
Bigram shingles are all the possible two-word sequences:
- Compare Bonsai
- Bonsai OpenSearch
- OpenSearch to
- to AWS
- AWS OpenSearch
Trigram shingles are all the possible three-word sequences:
- Compare Bonsai OpenSearch
- Bonsai OpenSearch to
- OpenSearch to AWS
- to AWS OpenSearch
After analysis (lowercase, stemming, stopword removal, shingling), we're left with the full list:
- compare bonsai
- compare bonsai opensearch
- bonsai opensearch
- bonsai opensearch _
- opensearch _
- opensearch _ aws
- _ aws
- _ aws opensearch
- aws opensearch
The _ denotes where stopwords are removed. This tells you, we're going to need some postprocessing once these
suggestions get returned. But that's really easy to do.
Add this to your config:
Filter
"bigrams_trigrams": {
"type": "shingle",
"min_shingle_size": 2,
"max_shingle_size": 3,
"output_unigrams": false
}
Analyzer
"analyze_shingles": {
"type": "custom",
"char_filter": [
"html_strip"
],
"tokenizer": "standard",
"filter": [
"lowercase",
"english_stop",
"bigrams_trigrams"
]
}
Field
"suggest_phrase": {
"type": "text",
"analyzer": "analyze_shingles",
"fielddata": true
}
With those in place, add suggest_phrase to your title and description copy_to's
// ...
"title": { "type": "text", "analyzer": "analyze_english", "copy_to":["completion","suggest_word","suggest_phrase"]},
"description": { "type": "text", "analyzer": "analyze_english", "copy_to":["completion","suggest_word","suggest_phrase"]},
// ...
Our completed configuration, ladies, gentlemen, and everyone in between:
Step 3: Suggest Phrases
# Step 3: Suggest Phrases
PUT /autocomplete-example/
{
"mappings": {
"properties": {
"docid": { "type": "keyword" },
"url": { "type": "keyword", "copy_to":["url_hierarchy"] },
"image": { "type": "keyword" },
"published": { "type": "date" },
"modified": { "type": "date" },
"author": { "type": "text", "analyzer": "analyze_names"},
"url_hierarchy":{ "type": "text", "analyzer": "analyze_urls"},
"url_depth": { "type": "integer" },
"title": { "type": "text", "analyzer": "analyze_english", "copy_to":["completion","suggest_word","suggest_phrase"]},
"description": { "type": "text", "analyzer": "analyze_english", "copy_to":["completion","suggest_word","suggest_phrase"]},
"body": { "type": "text", "analyzer": "analyze_english", "term_vector": "with_positions_offsets"},
"completion": { "type": "text", "analyzer": "edge_ngram_analyzer", "fields": { "raw": { "type": "keyword" } } },
"suggest_word": { "type": "text", "analyzer": "analyze_english_exactish", "fielddata": true},
"suggest_phrase": { "type": "text", "analyzer": "analyze_shingles", "fielddata": true}
}
},
"settings": {
"analysis": {
"filter": {
"english_stop": {
"type": "stop",
"stopwords": "_english_"
},
"english_stem": {
"type": "stemmer",
"language": "english"
},
"english_possessive_stem": {
"type": "stemmer",
"language": "possessive_english"
},
"bigrams_trigrams": {
"type": "shingle",
"min_shingle_size": 2,
"max_shingle_size": 3,
"output_unigrams": false
}
},
"tokenizer": {
"edge_ngram_tokenizer": {
"type": "edge_ngram",
"min_gram": 1,
"max_gram": 25,
"token_chars": ["letter", "digit", "punctuation"]
},
"path_hierarchy_tokenizer": {
"type": "path_hierarchy"
}
},
"analyzer": {
"analyze_urls": {
"type": "custom",
"tokenizer": "path_hierarchy_tokenizer"
},
"edge_ngram_analyzer": {
"type": "custom",
"tokenizer": "edge_ngram_tokenizer",
"filter": [
"lowercase"
]
},
"analyze_names": {
"type": "custom",
"tokenizer": "standard",
"filter": [
"lowercase",
"english_possessive_stem"
]
},
"analyze_english": {
"type": "custom",
"char_filter": ["html_strip"],
"tokenizer": "standard",
"filter": [
"lowercase",
"english_possessive_stem",
"english_stop",
"english_stem"
]
},
"analyze_english_exactish": {
"type": "custom",
"char_filter": ["html_strip"],
"tokenizer": "standard",
"filter": [
"lowercase",
"english_possessive_stem",
"english_stop"
]
},
"analyze_shingles": {
"type": "custom",
"char_filter": ["html_strip"],
"tokenizer": "standard",
"filter": [
"lowercase",
"english_stop",
"bigrams_trigrams"
]
}
}
},
"index": {
"number_of_shards": 1,
"number_of_replicas": 1
}
}
}
POST _reindex
{
"source": {
"index": "bonsai"
},
"dest": {
"index": "autocomplete-example"
}
}
Query
We're just showing the phrase example here for now. It uses the same significant_terms agg technique, just on our new
suggest_phrase field.
POST /autocomplete-example/_search
{
"query": {
"match": {
"completion": "ope"
}
},
"aggs": {
"significant_phrases": {
"significant_terms": {
"field": "suggest_phrase",
"include": "ope.*",
"min_doc_count": 1
}
}
},
"_source": {
"include": [
"title",
"url"
]
},
"size": 0
}
Results look good but they need some postprocessing. That's fine. I've yet to run into a complex case where at least some middleware isn't required. After we put it all together, I'll give some examples in JavaScript (don't hate!)
{
"took": 14,
"timed_out": false,
"_shards": {
"total": 1,
"successful": 1,
"skipped": 0,
"failed": 0
},
"hits": {
"total": {
"value": 178,
"relation": "eq"
},
"max_score": null,
"hits": []
},
"aggregations": {
"significant_phrases": {
"doc_count": 178,
"bg_count": 259,
"buckets": [
{
"key": "opensearch _",
"doc_count": 8,
"score": 0.020451963135967675,
"bg_count": 8
},
{
"key": "opensearch bonsai",
"doc_count": 7,
"score": 0.017895467743971716,
"bg_count": 7
},
{
"key": "opensearch platform _",
"doc_count": 4,
"score": 0.010225981567983837,
"bg_count": 4
},
{
"key": "opensearch platform",
"doc_count": 4,
"score": 0.010225981567983837,
"bg_count": 4
},
{
"key": "opensearch _ solrcloud",
"doc_count": 3,
"score": 0.007669486175987881,
"bg_count": 3
},
{
"key": "open letter _",
"doc_count": 2,
"score": 0.005112990783991919,
"bg_count": 2
},
{
"key": "open letter",
"doc_count": 2,
"score": 0.005112990783991919,
"bg_count": 2
},
{
"key": "opensearch here _",
"doc_count": 2,
"score": 0.005112990783991919,
"bg_count": 2
},
{
"key": "opensearch clusters",
"doc_count": 2,
"score": 0.005112990783991919,
"bg_count": 2
},
{
"key": "opensearch here",
"doc_count": 2,
"score": 0.005112990783991919,
"bg_count": 2
}
]
}
}
}
When you eventually postprocess, you'll be left with the following autocomplete phrases:
- opensearch bonsai
- opensearch platform
- opensearch solrcloud
- open letter
- opensearch here
- opensearch clusters
These aren't amazing, but they're a good start,and in my opinion good enough to guide the user. Our example only has a small corpus to sample from and if we had lots more content these suggestions would improve. Give it a try on your content and see how it turns out!
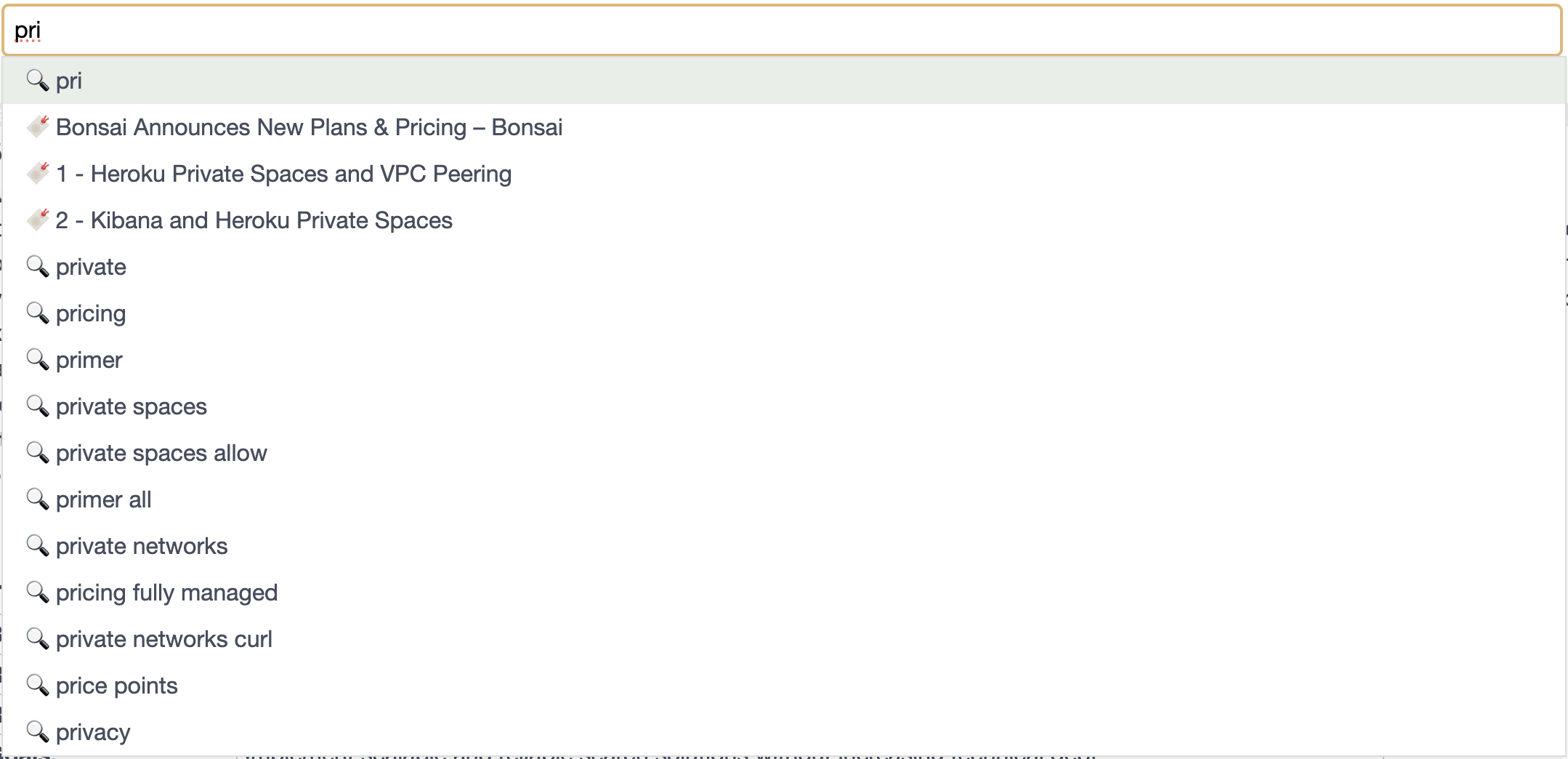
Our final query
No more scenery-chewing, here's the final completed query:
POST /autocomplete-example/_search
{
"query": {
"match": {
"completion": "ope"
}
},
"aggregations": {
"significant_words": {
"significant_terms": {
"field": "suggest_word",
"include": "ope.*",
"min_doc_count": 1
}
},
"significant_phrases": {
"significant_terms": {
"field": "suggest_phrase",
"include": "ope.*",
"min_doc_count": 1
}
}
},
"_source": {
"include": [
"title",
"url"
]
},
"size": 3
}
And the unprocessed results:
{
"took": 71,
"timed_out": false,
"_shards": {
"total": 1,
"successful": 1,
"skipped": 0,
"failed": 0
},
"hits": {
"total": {
"value": 178,
"relation": "eq"
},
"max_score": 6.6680512,
"hits": [
{
"_index": "autocomplete-example",
"_id": "bfb9fe25-8742-1067-026a-428025c41672",
"_score": 6.6680512,
"_source": {
"title": "Compare Bonsai OpenSearch to AWS OpenSearch",
"url": "https://bonsai.io/vs/amazon-opensearch-service"
}
},
{
"_index": "autocomplete-example",
"_id": "db637423-cf63-24c5-32ac-68c309c62fbe",
"_score": 6.501189,
"_source": {
"title": "Up and Running with OpenSearch – Bonsai",
"url": "https://bonsai.io/blog/up-and-running-with-opensearch"
}
},
{
"_index": "autocomplete-example",
"_id": "9a160271-5f4b-fc7f-1215-fdf63f2d9cc3",
"_score": 6.486245,
"_source": {
"title": "OpenSearch",
"url": "https://bonsai.io/category/opensearch"
}
}
]
},
"aggregations": {
"significant_words": {
"doc_count": 178,
"bg_count": 259,
"buckets": [
{
"key": "opensearch",
"doc_count": 35,
"score": 0.08947733871985859,
"bg_count": 35
},
{
"key": "open",
"doc_count": 4,
"score": 0.010225981567983837,
"bg_count": 4
},
{
"key": "operations",
"doc_count": 2,
"score": 0.005112990783991919,
"bg_count": 2
},
{
"key": "operational",
"doc_count": 1,
"score": 0.0025564953919959593,
"bg_count": 1
}
]
},
"significant_phrases": {
"doc_count": 178,
"bg_count": 259,
"buckets": [
{
"key": "opensearch _",
"doc_count": 8,
"score": 0.020451963135967675,
"bg_count": 8
},
{
"key": "opensearch bonsai",
"doc_count": 7,
"score": 0.017895467743971716,
"bg_count": 7
},
{
"key": "opensearch platform _",
"doc_count": 4,
"score": 0.010225981567983837,
"bg_count": 4
},
{
"key": "opensearch platform",
"doc_count": 4,
"score": 0.010225981567983837,
"bg_count": 4
},
{
"key": "opensearch _ solrcloud",
"doc_count": 3,
"score": 0.007669486175987881,
"bg_count": 3
},
{
"key": "open letter _",
"doc_count": 2,
"score": 0.005112990783991919,
"bg_count": 2
},
{
"key": "open letter",
"doc_count": 2,
"score": 0.005112990783991919,
"bg_count": 2
},
{
"key": "opensearch here _",
"doc_count": 2,
"score": 0.005112990783991919,
"bg_count": 2
},
{
"key": "opensearch clusters",
"doc_count": 2,
"score": 0.005112990783991919,
"bg_count": 2
},
{
"key": "opensearch here",
"doc_count": 2,
"score": 0.005112990783991919,
"bg_count": 2
}
]
}
}
}
Performance
One thing we didn't talk about yet, was speed. This is fast. I aim for less than 50ms. I'll take 70. Get worried when you start hitting 250 - the user would notice a lag and that's no fun. This is fast at query time because we're doing a lot up-front at index time. When things start getting slow, do the following, in this order:
- Talk to us at Bonsai and we'll make it fast for you.
Post-Processing
For post, here's what we need to do. On the browser I'm using autocomplete.js somewhere in the middle of the browser and the search engine I need to handle requests and post-process the get all this in a single list. In theory, you could implement this all on the client side, but I want the browser implementation to be minimal.
Here are the steps I need for post-processing:
- Transform the hits into
{ label, value }objects - Clean and transform the
significant_wordsagg bucket into{ label, value }objects - Clean and transform the
significant_phrasesagg bucket into{ label, value }objects
I'm not going to get into front-end design like CSS or icons, so for now I'll just use some emoji 😈
This is the full implementation. I'm sorry for the wall of code.
import { Client } from '@opensearch-project/opensearch'; // You can use Elastic too!
import pLimit from 'p-limit'; // requires `npm i p-limit`
const client = new Client({"node": process.env.BONSAI_URL}); // Point this at your search cluster
/*
Make our autocomplete query
*/
const getAutocompleteQuery = function(querystring,k) {
const pattern = `${querystring}.*`
return {
"query": {
"match": { "completion": querystring }
},
"aggregations": {
"significant_words": {
"significant_terms": {
"field": "suggest_word",
"include": pattern,
"min_doc_count": 2
}
},
"significant_phrases": {
"significant_terms": {
"field": "suggest_phrase",
"include": pattern,
"min_doc_count": 1
}
}
},
"_source": {"include":["title","url"]},
"size": k||3
}
}
/*
This uses the Analyzer on the server to normalize each suggested term!
We do this with concurrency to keep it fast
*/
const normalizeAutocomplete = async function(collection,texts,concurrent) {
const limit = pLimit(concurrent||10);
const tasks = texts.map(text =>
limit(async () => {
const res = await client.indices.analyze({
index:collection,
body: {
analyzer:"analyze_english",
text:text.replace(/[_]/g,' ').replace(/\s+/,' ').trim()
}
});
return {
q: text,
norm: res.body.tokens.map(t => t.token).join('_')
};
})
);
const results = await Promise.all(tasks);
return results;
};
/*
This is what your route will call, passing in the collection (index name), querystring prefix, and k page results
*/
export const autocomplete = async function(collection,querystring,k) {
const body = getAutocompleteQuery(querystring,k);
const results = await client.search({
index: collection,
body: body
});
//Keep track of everything
let texts = [];
let seen = [];
let resp = {
titles:[],
terms:[]
}
// Post-processor for normalized word and phrase suggestions
const term = function(t) {
if(!t || !t.q || !t.q.length || !t.norm || !t.norm.length) return;
const q = t.q.replace(/[_]/g,' ').replace(/\s+/,' ').trim();
const n = t.norm.replace(/[_]/g,' ').replace(/\s+/,' ').trim();
if(seen.indexOf(n)<0) {
seen.push(n);
resp.terms.push({
"label":'🔍 ' + q,
"value":`/sites/${collection}/search?q=${encodeURIComponent(q)}&s=${encodeURIComponent(querystring)}&p=${resp.terms.length}`
});
}
};
// Transform Opensearch response into the "resp" object
if(results && results.body) {
const b = results.body;
// Document hits, add to resp.titles
if(b.hits && b.hits.hits) {
resp.titles = b.hits.hits.map((r,i)=>{
return {
"label":'🔖 ' + r._source.title,
"value":`/sites/${collection}/redirect?u=${encodeURIComponent(r._source.url)}&s=${encodeURIComponent(querystring)}&p=${i}`
}
});
}
// Word suggestions
if(b.aggregations && b.aggregations.significant_words && b.aggregations.significant_words.buckets) {
texts = texts.concat(b.aggregations.significant_words.buckets.map(t=>t.key)).filter(v=>v&&v.length);
}
// Phrase suggestions
if(b.aggregations && b.aggregations.significant_phrases && b.aggregations.significant_phrases.buckets) {
texts = texts.concat(b.aggregations.significant_phrases.buckets.map(t=>t.key)).filter(v=>v&&v.length);
}
// Normalize and collapse the suggested search terms
let norms = await normalizeAutocomplete(collection,texts,20);
norms.forEach(term)
}
let auto = [{
"label":'🔍 ' + querystring,
"value":`/sites/${collection}/search?q=${encodeURIComponent(querystring)}&s=${encodeURIComponent(querystring)}&p=0`
}]
.concat(resp.titles)
.concat(resp.terms);
return auto;
}
const Autocomplete = { autocomplete };
export default Autocomplete;
OK! That was a lot. Let's admire the majesty of our completed solution
It's beautiful! I literally cried tears of joy.
Continue the adventure in Part 2: How to Really Scale Autocomplete
See you next time!
Further Reading
https://staff.fnwi.uva.nl/m.derijke/wp-content/papercite-data/pdf/cai-phd-thesis-2016.pdf
Ready to take a closer look at Bonsai?
Bonsai manages your search clusters and helps you achieve better search results for your users and your business. Find out if Bonsai is a good fit for you in just 15 minutes.
Learn how a managed service works and why it’s valuable to dev teams
You won’t be pressured or used in any manipulative sales tactics
We’ll get a deep understanding of your current tech stack and needs
Get the information you need to decide whether to go with Bonsai
