Last time, in Part 1, "How To Really Do Autocomplete", we covered a straightforward technique to build a quality autocomplete solution in pure Elasticsearch or OpenSearch. We used the significant_terms aggregation to provide diverse and helpful suggestions of words and phrases to help guide the user while they are typing a query. In this part, we'll scale it up to 6 million documents, and get 500 autocompletes-per-second at 30ms latency on a cluster that most teams probably run already.
Here’s what we’re going to build:
Our adventure continues
While Part 1 worked well and offered good suggestions for small datasets, it didn't scale for phrases the way I had it configured. The sweet spot for significant_phrases from Part 1 was for tens of thousands of docs. It turns out that as you add more and more documents and increase the variance and cardinality of the vocabulary, aggregating significant_terms on shingles gets really slow. And that's not fun.
I found this out because I was working on load testing a vector search cluster, and I had finished my goals for the week. I had millions of Wikipedia documents and vectors loaded into a nice set of data nodes. I wanted to get an index time comparison for lexical ingestion without vectors anyway, so I went side questing for an afternoon and said, “let's scale autocomplete, baby!” It was Friday and that's how I party.
I dropped in the components from Part 1 into my schema, turned off KNN, used a super fast Rust indexing client, and 5 minutes of ingestion later I had 6 million Wikipedia titles and abstracts ready for that sweet, sweet autocomplete query.
Fall from grace
Sad trombone. It was slow. Not just laggy - but failures everywhere. I tried warming the index but didn't get very far. CPU started screaming 🔥🔥😱😱 and almost all the queries were timing out. However when it did run, the word suggestions were amazing. They were exactly what I was hoping for, but I was feeling dejected that I might need to sacrifice the quality while getting it to work.
Success Example
Note the time. Over 4 seconds for a single autocomplete for 'tri'. Ouch. Also notice, the phrases aren't really that good!
{
"took": 4458,
"timed_out": false,
"_shards": {
"total": 2,
"successful": 2,
"skipped": 0,
"failed": 0
},
"hits": { ... },
"aggregations": {
"significant_words": {
"doc_count": 167796,
"bg_count": 5745033,
"buckets": [
{
"key": "tributary",
"doc_count": 21299,
"score": 4.207454601569715,
"bg_count": 21356
},
{
"key": "tribe",
"doc_count": 12849,
"score": 2.4987201587484775,
"bg_count": 13081
},
{
"key": "trial",
"doc_count": 9878,
"score": 1.9174879930694648,
"bg_count": 10074
},
{
"key": "trinity",
"doc_count": 8204,
"score": 1.600972838447807,
"bg_count": 8324
},
{
"key": "triple",
"doc_count": 6960,
"score": 1.3401736773540918,
"bg_count": 7154
},
{
"key": "trio",
"doc_count": 6701,
"score": 1.311448880959107,
"bg_count": 6780
},
{
"key": "trilogy",
"doc_count": 5123,
"score": 0.9971466407544656,
"bg_count": 5211
}
]
},
"significant_phrases": {
"doc_count": 167796,
"bg_count": 5745033,
"buckets": [
{
"key": "tributary _",
"doc_count": 19116,
"score": 3.776251688799064,
"bg_count": 19167
},
{
"key": "tributary _ _",
"doc_count": 15915,
"score": 3.146240861011439,
"bg_count": 15946
},
{
"key": "tribe _",
"doc_count": 6226,
"score": 1.2126146642013433,
"bg_count": 6329
},
{
"key": "trial _",
"doc_count": 5283,
"score": 1.0306112391930962,
"bg_count": 5362
}
]
}
}
}
Shortly after, I singled out significant_phrases aggregation as the culprit. Just plain unusable when doing an agg and include pattern at that cardinality of millions of docs. Shingles really explodes the set, and sadly it must go. I also wasn't too pleased with the quality for completions for the titles, so I had to start coming up with replacements for both.
Rebuild
I started with the completions analyzer for both titles and text. An out-of-the-box search-as-you-type field on titles works well and is really fast, memory wise looked good, and it was very simple to implement. It's still using edge_ngrams and shingles behind the scenes, but when isolating on titles and coupled with max shingle size of 3 it performed surprisingly well compared to my custom implementation.
Even with an updated completions field, however, the page suggestions were still un-tuned for relevance. We need pages in the background - they provide a good match set for the word and phrase suggestion aggregations to ensure good performance, but I wanted to get them somewhat decent. Luckily, the dataset has a 'views' column, which is the accumulated number of views for the page. This turned out to be a far better signal for relevance than the completions match_phrase_prefix score, so I use that as the primary ranking feature.
This is the pages query I arrived at with about 10 minutes of tuning. It can certainly be improved further, but my focus for this exercise was on scaling and not relevance tuning:
{
"query": {
"function_score": {
"query": {
"match_phrase_prefix": {
"completions": {
"query": q,
"boost": 0.01
}
}
},
"field_value_factor": {
"field": "views",
"factor": 1.0,
"modifier": "log1p",
"missing": 0
},
"boost_mode": "sum"
}
},
...
}
The next to go was, of course, the significant_phrases aggregations. We don't need to actually change the schema for this, we just need to change the query, and it is an easy thing to remove. Our replacement is now just a regular terms agg. This works great! It's fast and honestly much better in terms of quality.
Here's how it works: we perform a match of the prefix in the completions field, and that narrows the result set down to thousands of documents from millions. With this narrow scope, the significant_words and phrase terms aggregations are very fast, and the quality is laudable. Here is the aggs portion of the query:
{
...
"aggs": {
"significant_words": {
"significant_terms": {
"field": "suggest_word_all",
"min_doc_count": 1,
"include": q+'.*'
}
},
"significant_phrases": {
"terms": {
"field": "suggest_phrase",
"order": { "_count": "desc" },
"include": q+'.*',
"min_doc_count": 1
}
}
},
...
}
Find out how we can help you.
Schedule a free consultation to see how we can create a customized plan to meet your search needs.
Recovery
Here's the new schema and query in their entirety. You'll notice some fields look slightly different from Part 1, but this is a different dataset. I used the same names of things where appropriate.
Schema (mappings and settings)
{
"mappings": {
"properties": {
"id": { "type": "keyword" },
"title": { "type": "text",
"analyzer": "analyze_english",
"copy_to": [ "completions", "suggest_word", "suggest_word_all", "suggest_phrase" ]
},
"text": { "type": "text",
"analyzer": "analyze_english",
"copy_to": [ "suggest_word_all" ]
},
"url": { "type": "keyword" },
"wiki_id": { "type": "keyword" },
"views": { "type": "float" },
"paragraph_id": { "type": "integer" },
"langs": { "type": "keyword" },
"completions": {"type": "search_as_you_type", "max_shingle_size": 3 },
"suggest_word": {
"type": "text",
"analyzer": "analyze_suggest_word",
"search_analyzer": "analyze_suggest_search",
"fielddata": true
},
"suggest_word_all": {
"type": "text",
"analyzer": "analyze_suggest_word",
"search_analyzer": "analyze_suggest_search",
"fielddata": true
},
"suggest_phrase": {
"type": "text",
"analyzer": "analyze_suggest_phrase",
"search_analyzer": "analyze_suggest_search",
"fielddata": true
}
}
},
"settings": {
"analysis": {
"char_filter": {
"strip_html": { "type": "html_strip" }
},
"filter": {
"english_stop": {
"type": "stop",
"stopwords": "_english_"
},
"english_light_stem" : {
"type" : "stemmer",
"language" : "light_english"
},
"english_possessive_stem": {
"type": "stemmer",
"language": "possessive_english"
},
"shingles": {
"type": "shingle",
"min_shingle_size": 2,
"max_shingle_size": 4,
"output_unigrams": false
}
},
"analyzer": {
"analyze_english": {
"tokenizer": "standard",
"char_filter": ["html_strip"],
"filter": ["lowercase", "english_possessive_stem", "english_stop", "english_light_stem" ]
},
"analyze_suggest_word": {
"tokenizer": "standard",
"char_filter": [ "html_strip" ],
"filter": [ "lowercase", "english_stop" ]
},
"analyze_suggest_phrase": {
"tokenizer": "standard",
"char_filter": [ "strip_html" ],
"filter": [ "lowercase", "english_stop", "shingles", "unique" ]
},
"analyze_suggest_search": {
"tokenizer": "standard",
"char_filter": [ "strip_html" ],
"filter": [ "lowercase", "english_stop" ]
}
}
}
}
}
Query
{
"query": {
"function_score": {
"query": {
"match_phrase_prefix": {
"completions": {
"query": q,
"boost": 0.01
}
}
},
"field_value_factor": {
"field": "views",
"factor": 1.0,
"modifier": "log1p",
"missing": 0
},
"boost_mode": "sum"
}
},
"aggs": {
"significant_words": {
"significant_terms": {
"field": "suggest_word_all",
"min_doc_count": minwords,
"include": q+'.*'
}
},
"significant_phrases": {
"terms": {
"field": "suggest_phrase",
"order": { "_count": "desc" },
"include": q+'.*',
"min_doc_count": minwords
}
}
},
"_source": {"include": ["title", "url" ] },
"size": 3
}
Most importantly, the results are good AND it scales! I'm getting consistent sub-50ms on a warm index even when I'm hammering the cluster - which I do in the next section.
Load Testing
To ensure we're actually able to handle load, we need to test. And to do so we also need to ensure we're not just hitting cache.
I use the following methodology: source a list of thousands of prefixes, and test by running those as our prefix queries at high load. Obtaining prefixes is quite easy. If you're on Mac or Linux, you have access to the /usr/share/dict/words file. This is a convenient, plaintext, flat dictionary that has various uses. With some Python we can source all the 3-letter and 4-letter prefixes with these 7 lines of code:
import os
with open("/usr/share/dict/words", "r", encoding="utf-8") as f:
lines = f.read().lower().splitlines()
threes = [l[:3] for l in lines if len(l)>2]
fours = [l[:4] for l in lines if len(l)>3]
prefixes = list(set(threes + fours))
print(prefixes)
This gives us 24509 prefixes in total for the English dictionary.
With the prefixes, we can run the load test. I used Locust (no affiliation), which is really easy to setup and use with uvx. All we need are the prefixes, the query, and an easy to configure handler.
🥁🥁🥁 And the results!
Autocomplete Results
Look at these numbers. Absolutely beautiful.
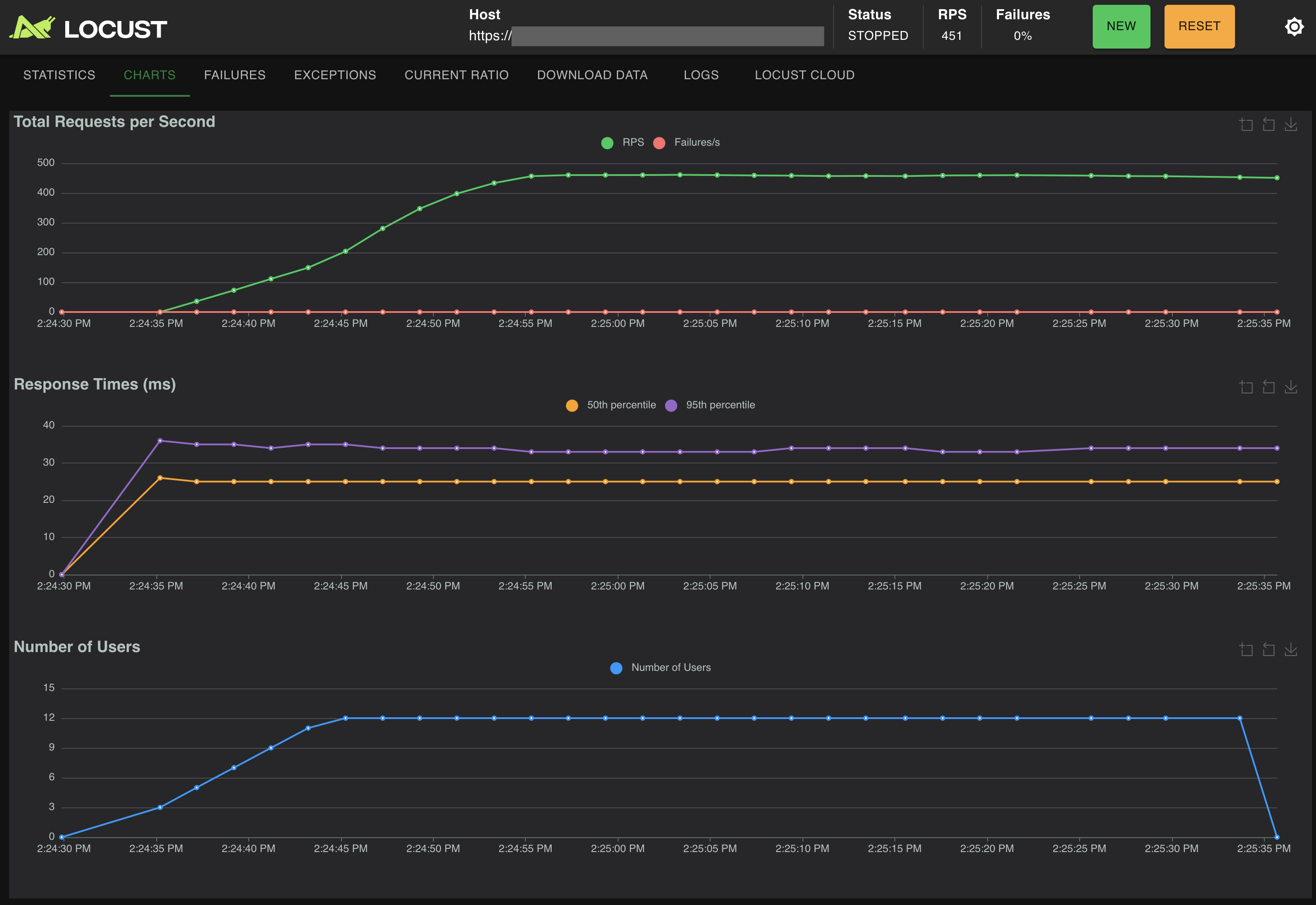
Request Summary (requests/second)
| Name | req/s | fails | Avg | Min | Max | Med |
|---|---|---|---|---|---|---|
| autocomplete | 416.02 | 0 | 25 | 17 | 275 | 25 |
| Aggregated | 416.02 | 0 | 25 | 17 | 275 | 25 |
Response Time Percentiles (milliseconds)
| Name | 50% | 75% | 95% | 99% | 99.99% | 100% |
|---|---|---|---|---|---|---|
| autocomplete | 23 | 26 | 31 | 45 | 130 | 210 |
| Aggregated | 23 | 26 | 31 | 45 | 130 | 210 |
We can see a clear sub-50ms query time at p99, running ~450qps once the concurrency rampup finishes and the index is warm. This is very fast, and very production ready. If you want to isolate your autocomplete infrastructure, you can achieve this on a standalone pair of instances (one for replication) with 4 vCPUs and 8GB RAM each.
Autocomplete and Vector Search on the same cluster
Remember earlier in the article, why I had this cluster in the first place? I am also running another large 31M document vector search index. Since I have two different indices, with two different use cases, I ran another test - simultaneous autocomplete and hybrid (lexical+vector+aggs) search load. The QPS number drops which is expected, but I'm very pleased with this result. The cluster will easily support the needs of both search and autocomplete.
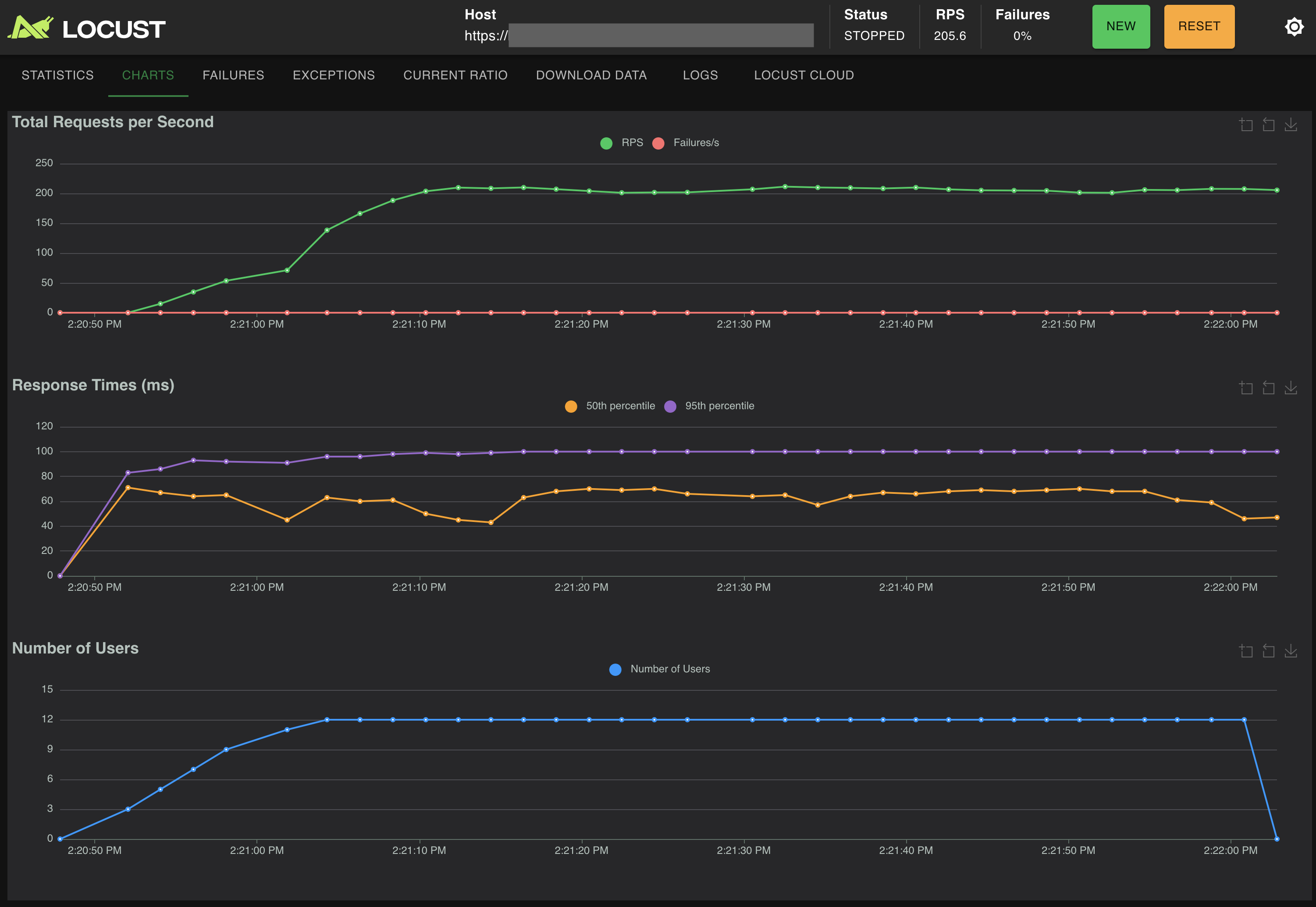
Request Summary (requests/second)
| Name | req/s | fails | Avg | Min | Max | Med |
|---|---|---|---|---|---|---|
| autocomplete | 95.33 | 0 | 27 | 16 | 131 | 26 |
| hybrid | 96.42 | 0 | 86 | 56 | 279 | 84 |
| Aggregated | 191.75 | 0 | 57 | 16 | 279 | 65 |
Response Time Percentiles (milliseconds)
| Name | 50% | 75% | 95% | 99% | 99.99% | 100% |
|---|---|---|---|---|---|---|
| autocomplete | 26 | 30 | 40 | 58 | 130 | 130 |
| hybrid | 84 | 92 | 110 | 130 | 280 | 280 |
| Aggregated | 65 | 84 | 100 | 120 | 280 | 280 |
Implementation Notes
Here are some important implementation specifics to keep it snappy:
- In most cases, you should use a separate index for autocomplete than your regular search. They have different profiles and scaling needs and the engine will work better when they are separate.
- When the user is typing, don't send a request for autocomplete immediately - wait 25ms to 50ms for them to pause beforehand. This will save on requests and only suggest when the user briefly pauses to think. Nick told me this is called “debouncing” which was a new fun term for me.
- For your dataset, experiment with your match prefix query and what goes into the
completionsfield. This will make a big impact on the seeded documents from which to draw your aggregations. - One area to watch is the
fielddataproperty of the aggregation fields. If you have a much larger corpus of documents or your cluster is too small, then you might have to make concessions there.
Co-Occurrence Sugar
When your corpus is huge, people have a much harder time understanding what's available. We can attribute this to the discovery problem: you don't know what you're missing, or even if you should be looking. So, as search engineers, we can and should come up with ways to help guide you and show you what's out there.
Once you've chosen a suggestion from autocomplete, drawn from a corpus of millions, there could be hundreds or thousands of results that match the selection. Yes, relevance tuning should take care of what shows up on the first page, but if our concept is broad there are likely hidden gems buried in the results, and they are left for the user to blindly explore with query refinement.
We can help improve this discovery with some UX by showing narrow navigation paths using suggestions to help guide the user. We construct another query that uses our selection, and provide more terms for those guide paths. Here's the query we use. Pass in a pre-selected autocomplete suggestion and experiment with min_doc_count.
{
"query": {
"bool": {
"filter": {
"bool": {
"should": [
{"match_phrase": {"title": q}},
{"match_phrase": {"text": q}}
]
}
}
}
},
"aggs": {
"significant_words": {
"significant_terms": {
"field": "suggest_word_all",
"min_doc_count": 1,
"exclude": q
}
}
},
"size": 0
}
Here are some examples, straight from the engine:
- “elasticsearch”
['kibana', 'lucene', 'opensearch', 'solr', 'mongodb', 'trino', 'dashboards', 'postgresql', 'sql']
- “opensearch”
['kibana', 'elasticsearch', 'dashboards', 'dashboard', 'visualization', 'search', 'web', 'engines', 'data', 'source']
- “solr”
['vufind', 'elasticsearch', 'blacklight', 'repositories', 'apache', 'indexes', 'metadata', 'rails', 'search', 'analytics']
- “horse”
['horses', 'thoroughbred', 'stakes', 'racehorse', 'furlongs', 'racecourse', 'fillies', 'foaled', 'bred', 'race']
- “wolf”
["wolf's", 'rayet', 'lycosidae', 'howlin', 'pack', 'pardosa', 'retty', 'albach', 'canis', 'lycodon']
- “bonsai”
['gartneriet', 'vestdal', 'penjing', 'saikei', 'akadama', 'zoonami', 'elegantissima', 'hòn', 'osteomeles']
- “lucene”
['nutch', 'elasticsearch', 'hadoop', 'workflow', 'indexing', 'apache', 'repository', 'proprietary', 'java', 'search']
- “bidirectional encoder”
['encoder', 'nlp', 'leveraging', 'bidirectional', 'transformer', 'devlin', 'baseline', 'transformers', 'query', 'ubiquitous']
- “large language model”
['chatgpt', 'bigscience', "openai's", 'gpt', 'openai', 'megatron', 'chatbot', 'transformer', 'decoder', 'lm']
We call this co-occurrence of terms. With a fully formed concept, co-occurrence shows which terms appear in the same passages as that concept. Honestly, I could play with this all day. Too bad I need to tear down my test cluster. See you next time!
Ready to take a closer look at Bonsai?
Bonsai manages your search clusters and helps you achieve better search results for your users and your business. Find out if Bonsai is a good fit for you in just 15 minutes.
Learn how a managed service works and why it’s valuable to dev teams
You won’t be pressured or used in any manipulative sales tactics
We’ll get a deep understanding of your current tech stack and needs
Get the information you need to decide whether to go with Bonsai
